|
当前版本仍在开发中,尚不被视为稳定版本。最新稳定版请使用 Spring Batch 文档 6.0.2! |
控制 Step 流程
当你能够在一个 job 中把多个 step 组织起来之后,就自然需要去控制这个 job
如何从一个 step “流转”到下一个 step。某个 Step 失败,并不一定意味着整个 Job 就必须失败。
此外,“成功”也未必只有一种含义,不同的成功结果可能决定下一步应执行不同的 Step。
根据一组 Step 的配置方式不同,某些 step 甚至可能完全不会被执行。
|
流程定义中的 Step Bean 方法代理
在一个流程定义中,step 实例必须是唯一的。当一个 step 在流程定义中存在多个走向时,
务必确保传递给流程定义方法(如 在下面的示例中,step 都是以参数形式注入到 flow 或 job 的 bean 定义方法中的。
这种依赖注入风格可以保证流程定义中的 step 唯一性。
但如果你是通过直接调用带有 关于 Spring Framework 中 bean 方法代理的更多细节,可参见 Using the @Configuration annotation 一节。 |
顺序流程
最简单的流程场景,就是一个 job 中所有 step 按顺序依次执行,如下图所示:
这可以通过在 step 中使用 next 来实现。
-
Java
-
XML
下面的示例展示了如何在 Java 中使用 next() 方法:
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.next(stepB)
.next(stepC)
.build();
}下面的示例展示了如何在 XML 中使用 next 属性:
<job id="job">
<step id="stepA" parent="s1" next="stepB" />
<step id="stepB" parent="s2" next="stepC"/>
<step id="stepC" parent="s3" />
</job>在上述场景中,stepA 会最先运行,因为它是列出的第一个 Step。
如果 stepA 正常完成,则继续运行 stepB,以此类推。
但如果 stepA 失败,那么整个 Job 就会失败,stepB 也不会执行。
在 Spring Batch 的 XML 命名空间中,配置里列出的第一个 step
总是该 Job 最先执行的 step。其余 step 元素的顺序无关紧要,
但第一个 step 必须始终排在 XML 的最前面。
|
条件流程
在前面的示例中,只有两种可能:
-
step成功,然后执行下一个step。 -
step失败,因此整个job也应失败。
在很多场景下,这已经够用了。但如果某个 step 失败后,
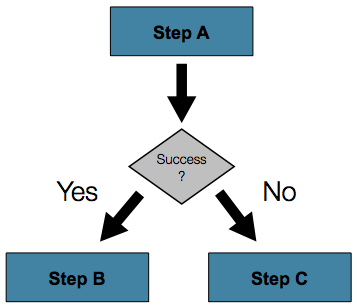
你希望触发另一个不同的 step,而不是让作业直接失败,又该怎么办?
下图展示了这样一种流程:
-
Java
-
XML
Java API 提供了一组链式方法,用来定义流程以及某个 step 失败时应采取的处理方式。下面的示例展示了如何先执行一个 step(stepA),然后根据
stepA 是否成功,继续进入两个不同的 step(stepB 或 stepC)之一:
@Bean
public Job job(JobRepository jobRepository, Step stepA, Step stepB, Step stepC) {
return new JobBuilder("job", jobRepository)
.start(stepA)
.on("*").to(stepB)
.from(stepA).on("FAILED").to(stepC)
.end()
.build();
}为了处理更复杂的场景,Spring Batch 的 XML 命名空间允许你在 step 元素内部定义转换元素。其中一种转换就是 next
元素。和 next 属性一样,next 元素用于告诉 Job 下一步要执行哪个 Step。但与属性不同的是,一个给定的
Step 上可以声明任意多个 next 元素,而且在失败场景下没有默认行为。这意味着,一旦使用了转换元素,就必须把该
Step 的所有流转行为都显式定义出来。还要注意,单个 step 不能同时声明 next 属性和 transition 元素。
next 元素用来指定匹配模式,以及匹配成功后要执行的下一个 step,如下例所示:
<job id="job">
<step id="stepA" parent="s1">
<next on="*" to="stepB" />
<next on="FAILED" to="stepC" />
</step>
<step id="stepB" parent="s2" next="stepC" />
<step id="stepC" parent="s3" />
</job>-
Java
-
XML
使用 Java 配置时,on() 方法会通过一种简单的模式匹配机制,去匹配该 Step 执行完成后产生的 ExitStatus。
使用 XML 配置时,转换元素上的 on 属性同样采用简单的模式匹配机制,用来匹配该 Step 执行后产生的 ExitStatus。
模式中只允许使用两个特殊字符:
-
*匹配零个或多个字符 -
?恰好匹配一个字符
例如,c*t 可以匹配 cat 和 count,而 c?t 可以匹配 cat,但不能匹配 count。
虽然一个 Step 上声明的转换元素数量没有上限,但如果该 Step 执行后得到的 ExitStatus 没有被任何元素覆盖,
框架就会抛出异常,导致 Job 失败。框架会自动按“从最具体到最宽泛”的顺序排序这些转换。因此,即便把前面示例中
stepA 的声明顺序调换,FAILED 这个 ExitStatus 仍然会进入 stepC。
BatchStatus 与 ExitStatus
为 Job 配置条件流转时,理解 BatchStatus 和 ExitStatus 的区别非常重要。BatchStatus 是一个枚举,
同时作为 JobExecution 和 StepExecution 的属性存在,框架用它来记录 Job 或 Step 的状态。它可能的取值包括:
COMPLETED、STARTING、STARTED、STOPPING、STOPPED、FAILED、ABANDONED 和
UNKNOWN。这些值大都顾名思义:比如 COMPLETED 表示 step 或 job 已成功完成,FAILED 表示执行失败,等等。
-
Java
-
XML
下面的示例展示了在 Java 配置中使用 on 的写法:
...
.from(stepA).on("FAILED").to(stepB)
...下面的示例展示了在 XML 配置中使用 next 元素的写法:
<next on="FAILED" to="stepB" />乍看之下,on 似乎引用的是所属 Step 的 BatchStatus。但实际上,它引用的是该 Step 的
ExitStatus。顾名思义,ExitStatus 表示的是 Step 执行结束之后的状态。
-
Java
-
XML
使用 Java 配置时,前面示例中的 on() 方法匹配的是 ExitStatus 的退出码。
更具体地说,在 XML 配置中,前面示例里的 next 元素匹配的也是 ExitStatus 的退出码。
用自然语言来表达,就是:“如果退出码是 FAILED,就转到 stepB”。默认情况下,退出码总是与该 Step 的
BatchStatus 保持一致,所以前面的配置能够正常工作。但如果退出码需要与默认值不同,该怎么办?samples
项目中的 skip 示例 job 就是一个很好的例子:
-
Java
-
XML
下面的示例展示了在 Java 中如何处理自定义退出码:
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2, Step errorPrint1) {
return new JobBuilder("job", jobRepository)
.start(step1).on("FAILED").end()
.from(step1).on("COMPLETED WITH SKIPS").to(errorPrint1)
.from(step1).on("*").to(step2)
.end()
.build();
}下面的示例展示了在 XML 中如何处理自定义退出码:
<step id="step1" parent="s1">
<end on="FAILED" />
<next on="COMPLETED WITH SKIPS" to="errorPrint1" />
<next on="*" to="step2" />
</step>step1 有三种可能结果:
-
Step失败,此时整个 job 也应该失败。 -
Step成功完成。 -
Step成功完成,但退出码是COMPLETED WITH SKIPS。此时应执行另一个 step 来处理错误。
上述配置本身没有问题。不过,还需要有某种机制根据执行过程中是否发生记录跳过来修改退出码,如下例所示:
public class SkipCheckingListener implements StepExecutionListener {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
} else {
return null;
}
}
}上面的代码是一个 StepExecutionListener。它先检查该 Step 是否执行成功,然后再判断
StepExecution 的 skip 计数是否大于 0。如果两个条件都满足,就返回一个新的 ExitStatus,其退出码为
COMPLETED WITH SKIPS。
停止配置
在理解了 BatchStatus 和 ExitStatus 之后,一个自然的问题是:
Job 的 BatchStatus 和 ExitStatus 是如何确定的?对于 Step 来说,这些状态由实际执行的代码决定;
而对于 Job,它们则由配置来决定。
到目前为止,前面讨论过的所有 job 配置中,至少都会有一个不再向后流转的最终 Step。
-
Java
-
XML
下面的 Java 示例中,step 执行后,Job 就结束:
@Bean
public Job job(JobRepository jobRepository, Step step1) {
return new JobBuilder("job", jobRepository)
.start(step1)
.build();
}下面的 XML 示例中,step 执行后,Job 同样结束:
<step id="step1" parent="s3"/>如果一个 Step 没有定义任何转换,那么 Job 的状态按以下规则确定:
-
如果该
Step以FAILED的ExitStatus结束,那么Job的BatchStatus和ExitStatus都是FAILED。 -
否则,
Job的BatchStatus和ExitStatus都是COMPLETED。
这种结束批处理 job 的方式,对于某些场景已经足够,例如简单的顺序 step job。但在一些情况下,你可能需要自定义 job 的停止方式。
为此,Spring Batch 除了前面提到的 next 元素 之外,还提供了三个用于停止 Job 的转换元素。
这些停止元素会以特定的 BatchStatus 结束一个 Job。需要特别注意的是,这些停止转换元素不会影响 Job 中任何
Step 的 BatchStatus 或 ExitStatus,它们只会影响 Job 的最终状态。比如,完全可能出现这样一种情况:
job 中每个 step 的状态都是 FAILED,但整个 job 的状态却是 COMPLETED。
在某个 Step 处结束
把某个 step 配置为“结束点”,表示让 Job 以 COMPLETED 的 BatchStatus 停止。一个状态已是
COMPLETED 的 Job 不能再重启,框架会抛出 JobInstanceAlreadyCompleteException。
-
Java
-
XML
使用 Java 配置时,可以通过 end 方法实现这一点。end 方法还允许传入可选的 exitStatus 参数,用来
自定义 Job 的 ExitStatus。如果没有提供 exitStatus,则默认使用 COMPLETED,与 BatchStatus 保持一致。
使用 XML 配置时,可以通过 end 元素实现这一点。end 元素同样支持可选的 exit-code 属性,用来
自定义 Job 的 ExitStatus。如果没有指定 exit-code,默认值就是 COMPLETED,与 BatchStatus 保持一致。
看下面这个场景:如果 step2 失败,Job 会以 COMPLETED 的 BatchStatus 和
COMPLETED 的 ExitStatus 结束,同时不会执行 step3。否则,流程会继续进入 step3。需要注意的是,如果
step2 失败,整个 Job 也不能重启,因为它的状态已经是 COMPLETED。
-
Java
-
XML
下面的示例展示了对应的 Java 配置:
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2, Step step3) {
return new JobBuilder("job", jobRepository)
.start(step1)
.next(step2)
.on("FAILED").end()
.from(step2).on("*").to(step3)
.end()
.build();
}下面的示例展示了对应的 XML 配置:
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<end on="FAILED"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">在某个 Step 处失败结束
把某个 step 配置为在特定位置失败结束,表示让 Job 以 FAILED 的 BatchStatus 停止。与 end 不同,
Job 失败并不会阻止它后续被重新启动。
使用 XML 配置时,fail 元素同样支持可选的 exit-code 属性,用于自定义 Job 的 ExitStatus。
如果没有指定 exit-code,默认值就是 FAILED,与 BatchStatus 保持一致。
看下面这个场景:如果 step2 失败,Job 会以 FAILED 的 BatchStatus 和
EARLY TERMINATION 的 ExitStatus 停止,同时不会执行 step3。否则,流程继续进入 step3。另外,如果
step2 失败之后重启该 Job,执行会从 step2 重新开始。
-
Java
-
XML
下面的示例展示了对应的 Java 配置:
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2, Step step3) {
return new JobBuilder("job", jobRepository)
.start(step1)
.next(step2).on("FAILED").fail()
.from(step2).on("*").to(step3)
.end()
.build();
}下面的示例展示了对应的 XML 配置:
<step id="step1" parent="s1" next="step2">
<step id="step2" parent="s2">
<fail on="FAILED" exit-code="EARLY TERMINATION"/>
<next on="*" to="step3"/>
</step>
<step id="step3" parent="s3">在指定 Step 处停止 Job
把一个 job 配置为在特定 step 处停止,表示让该 Job 以 STOPPED 的 BatchStatus 结束。
停止 Job 可以为处理流程提供一个临时中断点,以便操作人员在重启 Job 之前执行某些操作。
-
Java
-
XML
使用 Java 配置时,stopAndRestart 方法需要指定一个重启目标 step,用来定义 Job 重启后应从哪里继续执行。
使用 XML 配置时,stop 元素必须提供 restart 属性,用来指定 Job 重启后从哪个 step 继续执行。
看下面这个场景:如果 step1 以 COMPLETE 结束,job 就会停止;一旦重启,执行将从 step2 开始。
-
Java
-
XML
下面的示例展示了对应的 Java 配置:
@Bean
public Job job(JobRepository jobRepository, Step step1, Step step2) {
return new JobBuilder("job", jobRepository)
.start(step1).on("COMPLETED").stopAndRestart(step2)
.end()
.build();
}下面的示例展示了对应的 XML 配置:
<step id="step1" parent="s1">
<stop on="COMPLETED" restart="step2"/>
</step>
<step id="step2" parent="s2"/>以编程方式决定流程走向
在某些场景下,仅凭 ExitStatus 还不足以决定下一步要执行哪个 step。这时可以使用
JobExecutionDecider 来辅助做出决策,如下例所示:
public class MyDecider implements JobExecutionDecider {
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
String status;
if (someCondition()) {
status = "FAILED";
}
else {
status = "COMPLETED";
}
return new FlowExecutionStatus(status);
}
}-
Java
-
XML
下面的示例展示了在 Java 配置中,如何把一个实现了 JobExecutionDecider 的 bean 直接传给 next 调用:
@Bean
public Job job(JobRepository jobRepository, MyDecider decider, Step step1, Step step2, Step step3) {
return new JobBuilder("job", jobRepository)
.start(step1)
.next(decider).on("FAILED").to(step2)
.from(decider).on("COMPLETED").to(step3)
.end()
.build();
}下面的示例 job 配置中,decision 用来指定要使用的 decider 以及所有相关的转换:
<job id="job">
<step id="step1" parent="s1" next="decision" />
<decision id="decision" decider="decider">
<next on="FAILED" to="step2" />
<next on="COMPLETED" to="step3" />
</decision>
<step id="step2" parent="s2" next="step3"/>
<step id="step3" parent="s3" />
</job>
<beans:bean id="decider" class="com.MyDecider"/>拆分流程
到目前为止,前面描述的所有场景都属于 Job 以线性方式逐个执行 step。除了这种常见形式之外,Spring Batch
还支持把一个 job 配置为并行流程。
-
Java
-
XML
基于 Java 的配置可以通过框架提供的 builder 来声明拆分流程。如下例所示,split 元素中可以包含一个或多个
flow 元素,用来定义完整的独立流程。split 元素也可以包含前面讨论过的各种转换元素,例如 next 属性,
以及 next、end、fail 等元素。
@Bean
public Flow flow1(Step step1, Step step2) {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1)
.next(step2)
.build();
}
@Bean
public Flow flow2(Step step3) {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3)
.build();
}
@Bean
public Job job(JobRepository jobRepository, Flow flow1, Flow flow2, Step step4) {
return new JobBuilder("job", jobRepository)
.start(flow1)
.split(new SimpleAsyncTaskExecutor())
.add(flow2)
.next(step4)
.end()
.build();
}XML 命名空间同样支持使用 split 元素。如下例所示,split 元素中可以包含一个或多个 flow 元素,
用于定义完整的独立流程。split 元素也可以包含前面讨论过的各种转换元素,例如 next 属性,或
next、end、fail 等元素。
<split id="split1" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>外部化流程定义与 Job 之间的依赖
job 中的部分流程可以被外部化为独立的 bean 定义,然后在多个地方复用。实现这一点有两种方式。第一种方式是把该流程声明为对外部已定义 flow 的引用。
-
Java
-
XML
下面的 Java 示例展示了如何把一个 flow 声明为对外部 flow 的引用:
@Bean
public Job job(JobRepository jobRepository, Flow flow1, Step step3) {
return new JobBuilder("job", jobRepository)
.start(flow1)
.next(step3)
.end()
.build();
}
@Bean
public Flow flow1(Step step1, Step step2) {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1)
.next(step2)
.build();
}下面的 XML 示例展示了如何把一个 flow 声明为对外部 flow 的引用:
<job id="job">
<flow id="job1.flow1" parent="flow1" next="step3"/>
<step id="step3" parent="s3"/>
</job>
<flow id="flow1">
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>像前面那样定义外部 flow,其效果是把该外部 flow 中的 step 插入到当前 job 中,就像这些 step 本来就是在这里内联声明的一样。 这样一来,多个 job 就可以引用同一个模板 flow,再把这些模板组合成不同的逻辑流程。这也是把各个 flow 的集成测试彼此拆开的好方法。
外部化 flow 的另一种形式是使用 JobStep。JobStep 与 FlowStep 类似,但它会针对所指定 flow 中的步骤,
真正创建并启动一个独立的 job execution。
-
Java
-
XML
下面的示例展示了 Java 中的 JobStep 写法:
@Bean
public Job jobStepJob(JobRepository jobRepository, Step jobStepJobStep1) {
return new JobBuilder("jobStepJob", jobRepository)
.start(jobStepJobStep1)
.build();
}
@Bean
public Step jobStepJobStep1(JobRepository jobRepository, JobLauncher jobLauncher, Job job, JobParametersExtractor jobParametersExtractor) {
return new StepBuilder("jobStepJobStep1", jobRepository)
.job(job)
.launcher(jobLauncher)
.parametersExtractor(jobParametersExtractor)
.build();
}
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// ...
.build();
}
@Bean
public DefaultJobParametersExtractor jobParametersExtractor() {
DefaultJobParametersExtractor extractor = new DefaultJobParametersExtractor();
extractor.setKeys(new String[]{"input.file"});
return extractor;
}下面的示例展示了 XML 中的 JobStep 写法:
<job id="jobStepJob" restartable="true">
<step id="jobStepJob.step1">
<job ref="job" job-launcher="jobLauncher"
job-parameters-extractor="jobParametersExtractor"/>
</step>
</job>
<job id="job" restartable="true">...</job>
<bean id="jobParametersExtractor" class="org.spr...DefaultJobParametersExtractor">
<property name="keys" value="input.file"/>
</bean>job parameters extractor 是一种策略,用来决定如何把该 Step 的 ExecutionContext 转换为所运行
Job 的 JobParameters。当你希望在 job 和 step 的监控、报表方面拥有更细粒度的控制能力时,JobStep 就非常有用。
此外,JobStep 往往也是回答“如何在 job 之间建立依赖关系?”这个问题的一个好方案。它适合把大型系统拆分成更小的模块,并控制 job 之间的流转。

